Analyzing two-way tables
| dplyr | tidyr |
|---|---|
| 1.0.3 | 1.1.2 |
Introduction
Before tackling two-way tables, let’s explore a simpler one-way table. The following dataset shows mean annual income by occupation for the year 2014 (src: Bureau of Labor Statistics)
| Income | |
|---|---|
| Architecture and Engineering | 112490 |
| Arts, Design, Entertainment, Sports, and Media | 72410 |
| Building and Grounds Cleaning and Maintenance | 83970 |
| Business and Financial Operations | 81520 |
| Community and Social Service | 70070 |
| Computer and Mathematical | 45310 |
| Construction and Extraction | 101110 |
| Education, Training, and Library | 52210 |
| Farming, Fishing, and Forestry | 55790 |
| Food Preparation and Serving Related | 76010 |
| Healthcare Practitioners and Technical | 28820 |
| Healthcare Support | 43980 |
| Installation, Maintenance, and Repair | 21980 |
| Legal | 26370 |
| Life, Physical, and Social Science | 24980 |
| Management | 38660 |
| Office and Administrative Support | 35530 |
| Personal Care and Service | 25160 |
| Production | 46600 |
| Protective Service | 45220 |
| Sales and Related | 35490 |
| Transportation and Material Moving | 34460 |
So, what can we glean from this dataset other than the raw values associated with each occupation type? For starters, we may be interested in coming up with a summary of income values such as the median, or $45265 in our working example. This is a single value that can be used to characterize the overall income value. However, the income values in our batch are not all equal to $45265–they vary above or below this median value. A good way to measure the variability about the median is to subtract the median income value from each occupation income value. We can do this in a table, but will choose a dotplot chart instead to facilitate comparison.
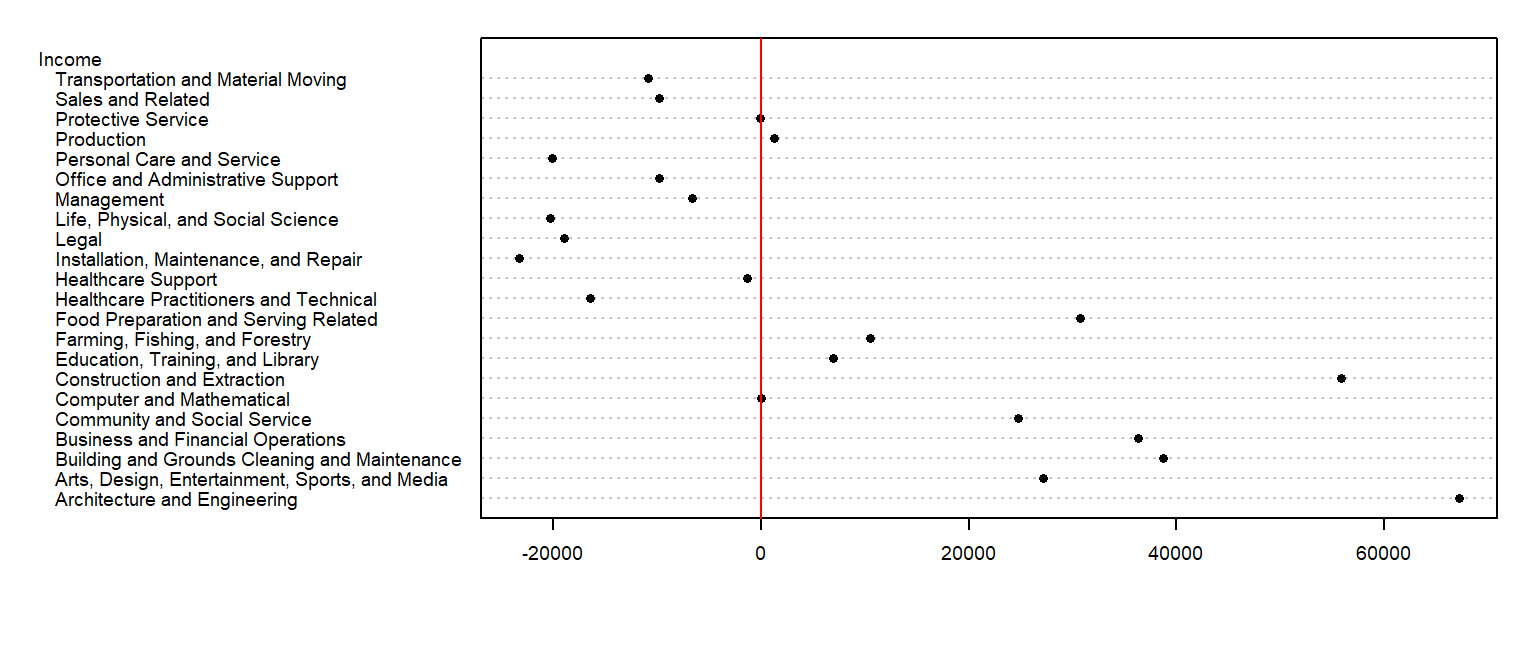
We have separated the income values into two parts: an overall value and the difference between each value and the overall (which we will refer to as the residuals). This can be written in the following algebraic form:
\[ Income_{Occupation} = Income_{median} + Income_{residual} \]
For example, ‘Healthcare Support’ average income of $43980 can be separated into the sum of the median, $45265, and the residual, $-1285.
So in addition to gleaning a median income value from this batch of values, we have also devised a way to facilitate the comparison of the income values to one another. Alternatively, we could have assigned colors to each cell of the table reflecting their values relative to the overall median.
The income value can be thought of as the response to the occupation type (also known as a factor). In other words, the factor determines the value in our table. We can re-write the last equation in a more formal way:
\[ y_{i} = \mu + \epsilon_i \]
where \(y_{i}\) is the response variable (e.g. income) for factor \(i\) (e.g. occupation), \(\mu\) is the overall typical value (hereafter referred to as the common value) and is usually the mean or median, and \(\epsilon_i\) is the residual. Next, we will see how the idea of separating the values into components can be expanded to two-way (aka two-factor) tables.
Anatomy of a two-way table
Let’s decompose the following table which represents infant mortality rates (per 1000 live births) by region and by a father’s educational attainment for the years 1964 through 1966 (Hoaglin et al.).

A two-way table is composed of three variables:
- a row factor which has four levels in our working example: Northeast, North Central, South and West,
- a column factor which has five levels in our working example: under 8, 9-11, 12, 13-15 and 16 and greater years of education,
- response variables of which we have 4 (rows) x 5 (columns) = 20 all together.
A two-way table is an extension to the one-way table described in the introduction where instead of grouping a continuous variable by a single factor category we explore the variable across two factor categories.
We can represent the relationship between the response variable, \(y\), and the two factors as:
\[ y_{ij} = \mu + \alpha_i + \beta_j + \epsilon_{ij} \]
where \(y_{ij}\) is the response variable for row \(i\) and column \(j\), \(\mu\) is the overall typical value (hereafter referred to as the common value), \(\alpha_i\) is the row effect, \(\beta_j\) is the column effect and \(\epsilon_{ij}\) is the residual or value left over after all effects are taken into account.
The goal of this analysis is to decompose the response variable into its respective effects–i.e. the two contributing factors: education of father and region–via an iterative process where row medians and column medians are removed from the response variables repeatedly until the row and column medians approach zero.
Analysis workflow
Let’s first create the dataframe.
df <- data.frame(row.names = c("NE","NC","S","W"),
ed8 = c(25.3,32.1,38.8,25.4),
ed9to11 = c(25.3,29,31,21.1),
ed12 = c(18.2,18.8,19.3,20.3),
ed13to15 = c(18.3,24.3,15.7,24),
ed16 = c(16.3,19,16.8,17.5)
)Visualizing the data
It’s often easier to look at a graphical representation of the data than a tabular one. Even a table as small as this can benefit from a plot.
We will adopt Bill Cleveland’s dotplot for this purpose. R has a built-in dotplot function called dotchart. It requires that the table be stored as a matrix instead of a dataframe; we will therefore convert df to a matrix by wrapping it with the as.matrix() function.
dotchart( as.matrix(df), cex=0.7)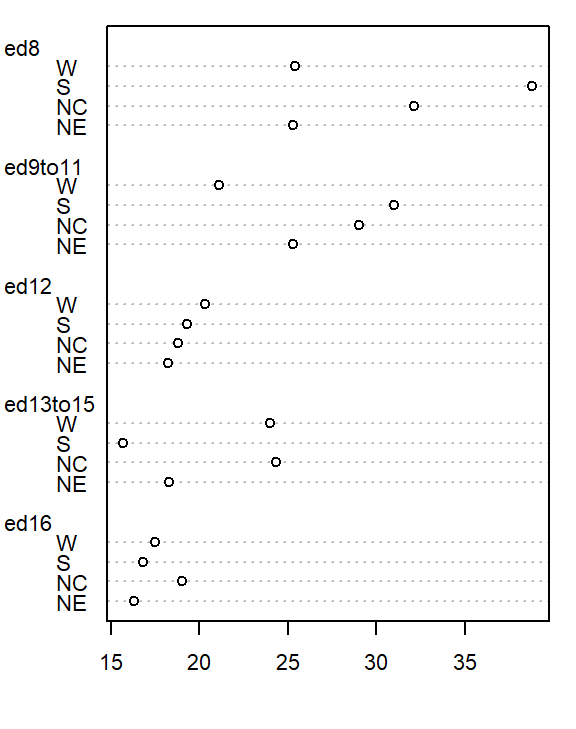
The plot helps visualize any differences in mortality rates across different father educational attainment levels. There seems to be a gradual decrease in child mortality with increasing father educational attainment.
But the plot does not help spot differences across regions (except for the ed12 group). We can generate another plot where region becomes the main grouping factor. We do this by wrapping the matrix with the transpose function t().
dotchart( t(as.matrix(df)), cex=0.7)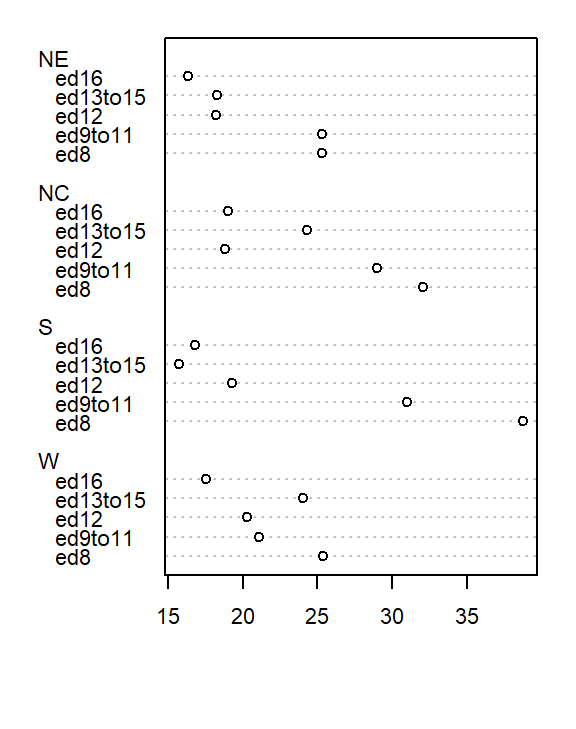
At first glance, there seems to be higher death rates for the NC and S regions and relatively lower rates for the W and NE regions. But our eyes may be fooled by outliers in the data.
Next, we’ll generate side-by-side boxplots to compare the effects between both categories. Note that we’ll need to create a long version of the table using the tidyr package.
library(tidyr)
library(dplyr)
df.l <- df %>%
mutate(Region = as.factor(row.names(.)) ) %>%
gather(key=Edu, value = Deaths, -Region) %>%
mutate(Edu = factor(Edu, levels=names(df)))
# side-by-side plot
OP <- par(mfrow=c(1,2))
plot(Deaths ~ Region + Edu, df.l)
par(OP)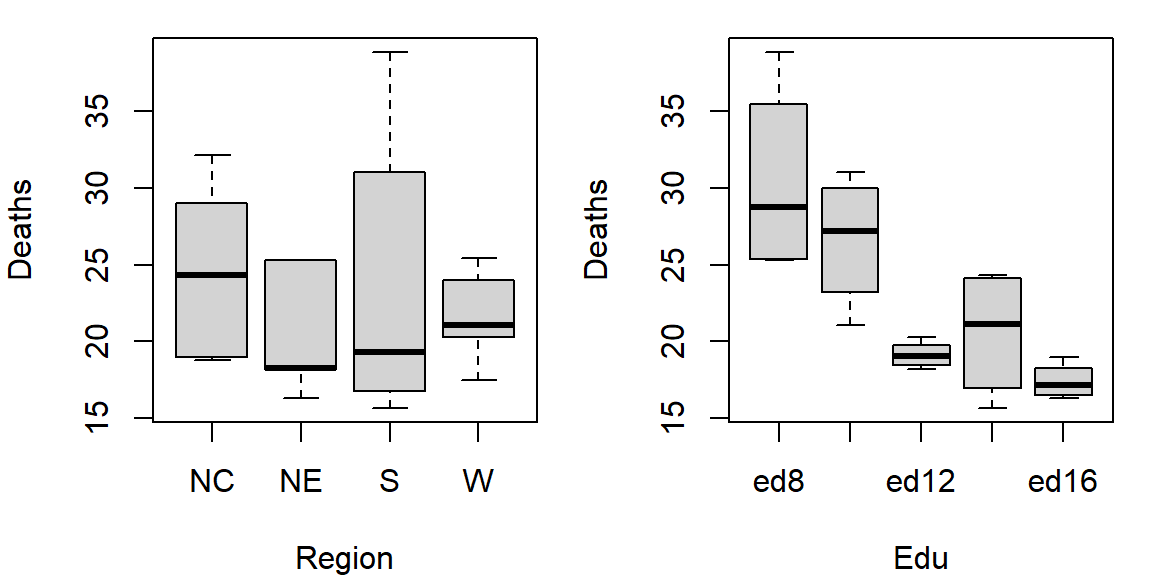
So at this point the plots suggest that there may be a father’s educational attainment effect as well as a regional effect on infant mortality with the former effect being possibly more important.
Next we will attempt to quantify these effects using Tukey’s median polish.
Median polish
Step 1: Compute overall median and residual table
First, we will compute the median value for all values in the dataset; this will be our first estimate of the common value. The resulting median value is placed in the upper left-hand margin of the table. A residual table is created by taking the difference between the original value and the overall median.
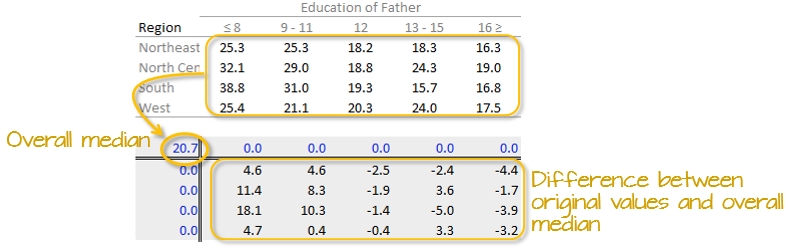
You’ll also note that the row and column effect values are initially populated with 0 values.
Step 2: Compute the row medians
Next, row medians are computed (shown in red in the following figure) from the residual table.
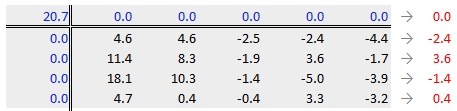
Note that in addition to computing the row median values for the response variable, we are also computing the median value for the column effects in the upper margin (which happens to be zero since we have no column effect values yet).
Step 3: Create a new residual table from the row medians
The row medians are added to the left hand margin of the new residual table (shown in green). These values represent the row effects in this first iteration. A new set of residual values is created from the row medians where each cell takes on the value of the subtraction of the row median from each response variable in that row.
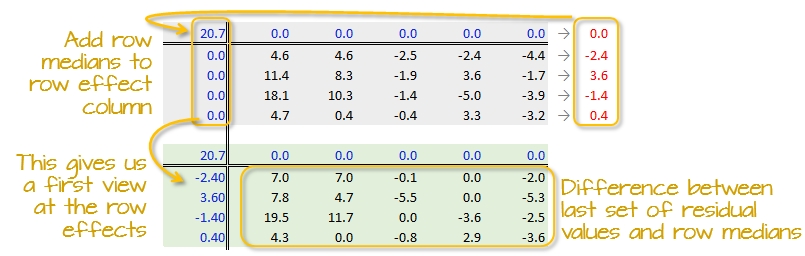
The subtraction is also done for the column effect values (even though all values remain zero) and the global median (common effect value).
Step 4: Compute the column medians
Next, column medians are computed (shown in red in the following figure) from the residual table. Note that you are NOT computing the column medians from the original response variables. Note too that we are also computing the median value for the row effect values (left margin).
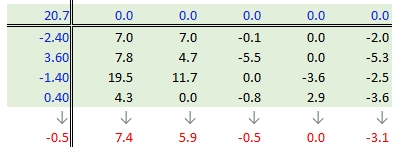
Step 5: Create a new residual table from the column medians
A new residual table is created from the column median where each new cell takes on the value of the subtraction of the column median from each initial residual value in that column. For example, the first upper-left cell’s residual is \(7.0 - 7.4 = -0.4\).
The column medians are also added to the column effect margin. Note that we are also adding the row effect median value, -0.5, to the common effect cell in the upper left-hand corner.
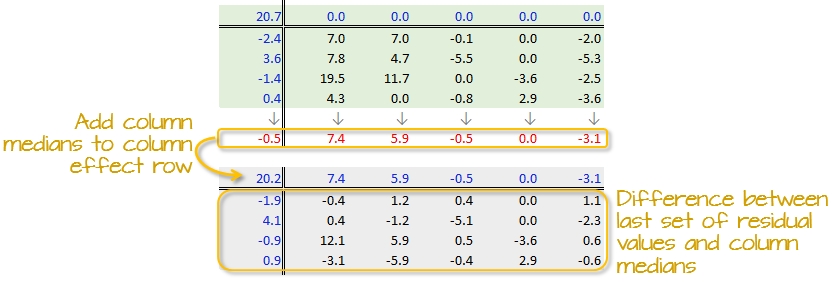
We have now completed our first row and column smoothing iteration. However, there may be more row and column effects that can be pulled from the residuals. We therefore move on to a second iteration.
Step 6: Second iteration – row effects
Next, we compute the row medians from the residuals, then add the column effect median to the top margin (and the common value) and subtract the row medians from the residuals. as in step 3.
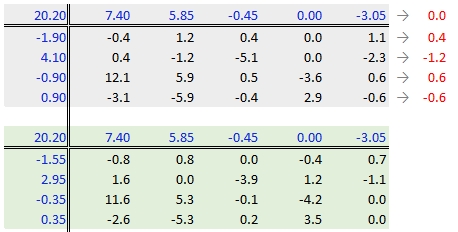
Step 7: Second iteration – column effects
To wrap-up the second iteration, we compute the column median values from the residuals then subtract the medians from those residuals. We also add the medians to the row effect values and the common value.
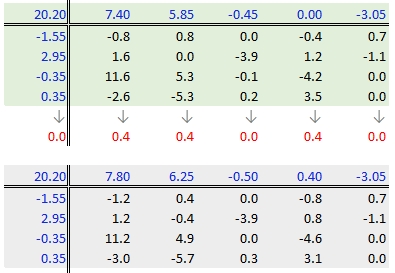
When do we stop iterating?
The goal is to iterate through the row and column smoothing operations until the row and column effect medians are close to 0. However, Hoaglin et al. (1983) warn against “using unrestrained iteration” and suggest that a few steps should be more than adequate in most instances. In our working example, a third iteration may be warranted. The complete workflow for this third iteration follows.
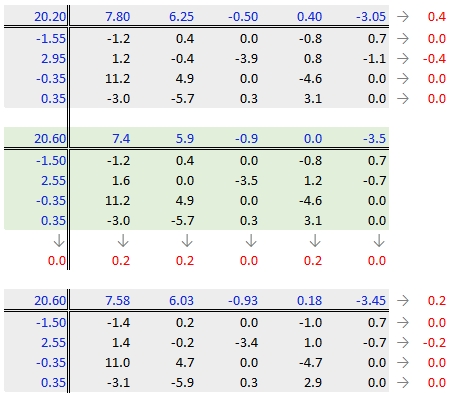
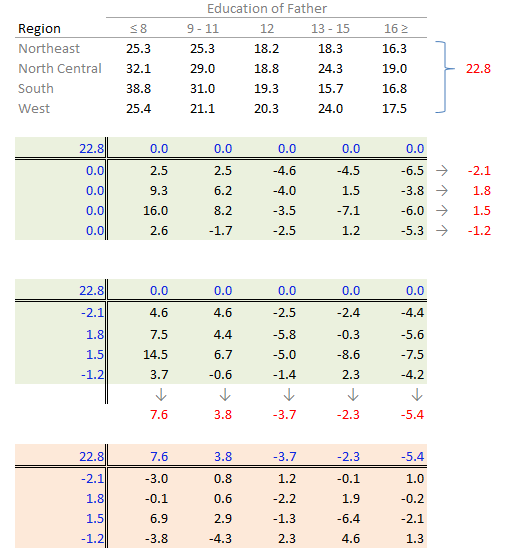
The final version of the table (along with the column and row values) is shown below:
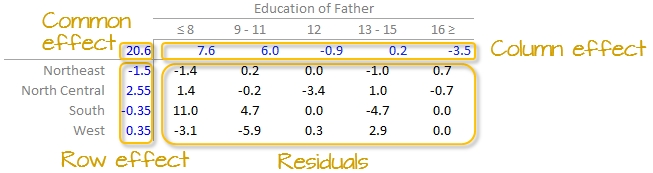
A progression of each iteration is shown side-by-side in the next figure. Note how, at the end of the iterations, the common factor ends up contributing the largest effect. Also note the one abnormally high residual in the southern region associated with 8th grade education.
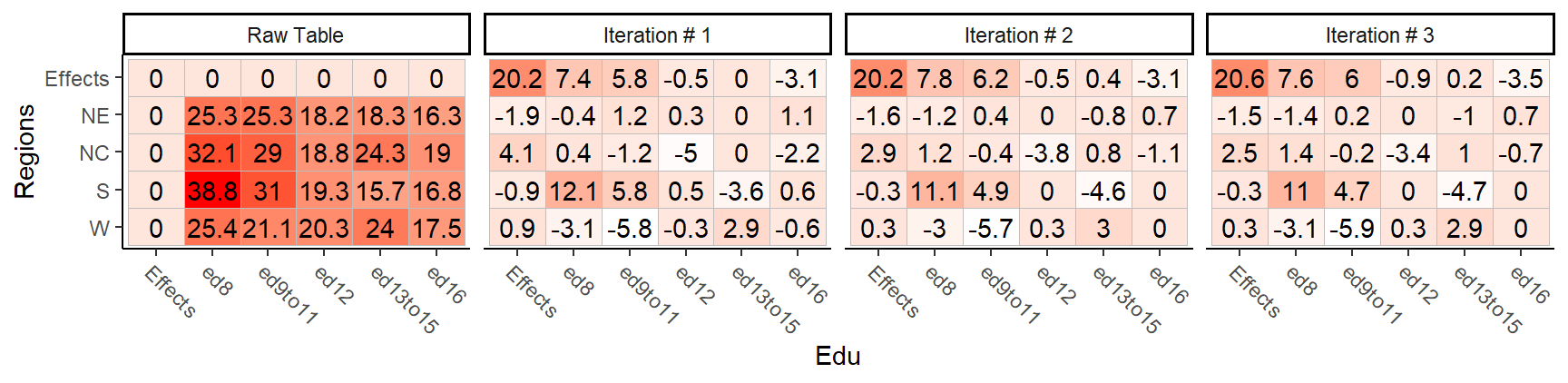
Interpreting the median polish
As noted earlier, a two-way table represents the relationship between the response variable, \(y\), and the two categories as:
\[ y_{ij} = \mu + \alpha_i + \beta_j + \epsilon_{ij} \]
In our working example, \(\mu\) = 20.6; \(\alpha_i\) = -1.5, 2.6 -0.4, and 0.4 for \(i\) = NE, Nc, S and W respectively; \(\beta_j\) = 7.6, 6.0, -0.9, 0.2 and -3.5 for \(j\) = ed8, ed9to11, ed12, ed13to15 and ed16 respectively.
The residuals represent the portion of the mortality rates that can’t be explained by either factors.
So the mortality rate in the upper left-hand cell from the original table can be deconstructed as:

The examination of the table suggests that the infant mortality rate is greatest for fathers who did not attain more than 8 years of school (i.e. who has not completed high school) as noted by the high column effect value of 7.6. This is the rate of infant mortality relative to the overall median (i.e. on average, 20.6 infants per thousand die every year and the rate goes up to 7.6 + 20.6 for infants whose father has not passed the 8th grade). Infants whose father has completed more than 16 years of school (i.e. who as completed college) have a lower rate of mortality as indicated by the low effect value of -3.5 (i.e. 3.5 fewer depths than average). The effects from regions also show higher infant mortality rates for North Central and Western regions (with effect values of 2.6 and 0.4 respectively) and lower rates for the northeastern and southern regions; however the regional effect does not appear to be as dominant as that of the father’s educational attainment.
It’s also important to look at the distribution of the residual numbers across the two-way table. One should identify unusually high or low residuals in the table. Such residuals may warrant further investigation (e.g. the high southern region residual value of 10.8 may need further exploration).
Test for non-additivity
Thus far, we have assumed an additive relationship between the effects (factors). But this additive model may not be the best fit for our data. A good way to test this is by generating a Tukey Additivity Plot where we plot residuals vs. the comparison value, \(cv_{ij}\), defined as \(\alpha_i \beta_j / \mu\). If the plot is devoid of any obvious trend or pattern we can conclude that our dataset is consistent with an additive model. Such seems to be the case with our working example as shown in the following plot.
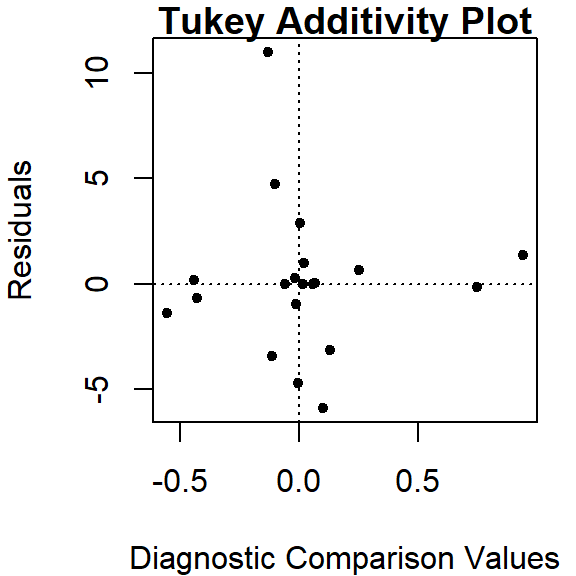
If the diagnostic plot revealed a trend, its shape–or more specifically, its slope–could be used in helping define an appropriate transformation for the data. A rule of thumb is to apply a \((1 – slope)\) power transformation to the original data. If the resulting power is not appropriate for the dataset then the \(cv_{ij}\) can be added to the additive model as follows:
\[ y_{ij} = \mu + \alpha_i + \beta_j + \alpha_i \beta_j / \mu + \epsilon_{ij} \]
Implementing the median polish in R
The steps outlined in the previous section can be easily implemented using pen and paper or a spreadsheet environment for larger datasets. R has a built-in function called medpolish() which does this for us. We can define the maximum number of iterations by setting the maxiter= parameter but note that medpolish will, by default, automatically estimate the best number of iterations for us. We’ll set it to 3 to match the three iterations conducted in the previous selection.
df.med <- medpolish( df , maxiter=3)1: 47.1
2: 42.9
3: 42.45The three values printed to the console gives us the sum of absolute residuals at each iteration; we will ignore these numbers. The output from the model is stored in the df.med object. To see its contents , simply type it at the command line.
df.med
Median Polish Results (Dataset: "df")
Overall: 20.6
Row Effects:
NE NC S W
-1.50 2.55 -0.35 0.35
Column Effects:
ed8 ed9to11 ed12 ed13to15 ed16
7.575 6.025 -0.925 0.175 -3.450
Residuals:
ed8 ed9to11 ed12 ed13to15 ed16
NE -1.375 0.175 0.025 -0.975 0.65
NC 1.375 -0.175 -3.425 0.975 -0.70
S 10.975 4.725 -0.025 -4.725 0.00
W -3.125 -5.875 0.275 2.875 0.00All three effects are displayed as well as the residuals (note that the precision returned is greater than that used in our earlier analysis).
To generate the Tukey additivity plot, simply wrap the median polish object with the plot command as in:
plot( df.med )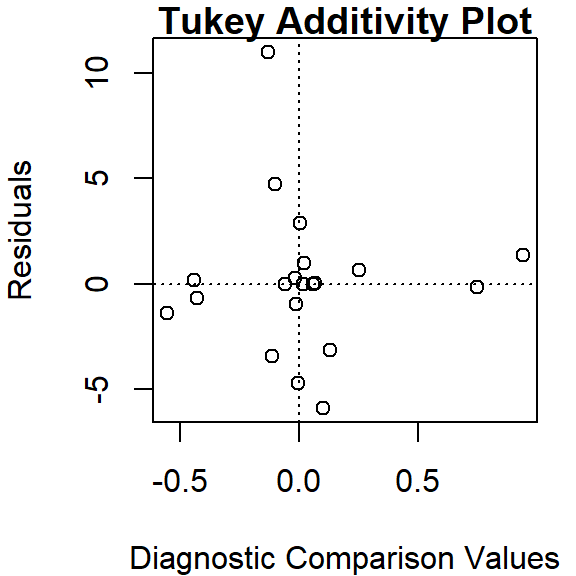
What if we use the mean instead of the median?
The procedure is similar with some notable differences. First, we compute the global mean instead of the medians (the common effect) then subtract it from all values in the table. Next, we compute the row means (the row effect) then subtract each mean from all values in its associated row. We finally compute the column means (from the residuals) to give us the column effect. That’s it, unlike the median polish, we do not iterate the smoothing sequences. An example of a “mean” polish applied to our data follows:
The results differ slightly from those produced using the median polish. Recall that the mean is sensitive to outliers and medians are not. If a robust estimate of the effects is sought, stick with the median polish.
So what can we gain from the “mean” polish? Well, as it turns out, it serves as the basis of the two-way ANOVA.
Two-way ANOVA
A two-way ANOVA assesses whether the factors (categories) have a significant effect on the outcome. Its implementation can be conceptualized as a regression analysis where each row and column level is treated as a dummy variable. The computed regression coefficients are the same as the levels computed using the “mean” polish outlined in the previous step except for one notable difference: the ANOVA adds one of the column level values and one of the row level values to the grand mean then subtracts those values from their respective row/column effects.
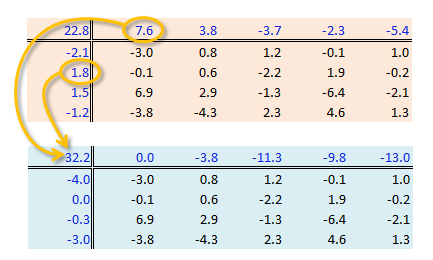
The resulting row/column levels are the regression coefficients:
M <- lm(Deaths ~ Edu + Region, df.l)
coef(M)(Intercept) Edued9to11 Edued12 Edued13to15 Edued16 RegionNE RegionS RegionW
32.215 -3.800 -11.250 -9.825 -13.000 -3.960 -0.320 -2.980 The regression formula takes on the form:
\[ Deaths = 32.21 - 3.8(ed9to11) -11.25(ed12) -9.83(ed13to15) -13(ed16) \\ -3.96(RegionNE) -0.320(RegionS) -2.980(RegionW) + \epsilon_{ij} \]
So, for example, to compute the first value in the raw table (death rate = 25.3) from the formula, substitute the variables as follows:
\[ Deaths = 32.21 - 3.8(0) -11.25(0) -9.83(0) -13(0) \\ -3.96(1) -0.320(0) -2.980(0) - 3.0 \\ = 32.21 -3.96 -3.0 \\ = 25.3 \]
To assess if any of the factors have a significant effect on the Death variables, simply wrap the regression with an anova() function.
anova(M)Analysis of Variance Table
Response: Deaths
Df Sum Sq Mean Sq F value Pr(>F)
Edu 4 478.52 119.630 7.7539 0.00251 **
Region 3 57.44 19.146 1.2410 0.33801
Residuals 12 185.14 15.428
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The results suggest that the father’s educational attainment has a significant effect on infant mortality (p = 0.0025) whereas the region does not (p = 0.338).
References
Understanding Robust and Exploratory Data Analysis, D.C. Hoaglin, F. Mosteller and J.W. Tukey, 1983.
 Manny Gimond (2021)
Manny Gimond (2021)