Data manipulation examples
| dplyr | tidyr | stringr |
|---|---|---|
| 1.0.3 | 1.1.2 | 1.4.0 |
The following data are used in some of the subsequent tutorials (including the one on ggplot2) and make use of some advanced data manipulation routines. The input data file formats are provided as is by their source and are modified to facilitate ingestion into some the plotting routines covered in later exercises. Data used in this tutorial include grain harvest for north america and income/education census data for the US.
dat1 <- read.csv("http://mgimond.github.io/ES218/Data/FAO_grains_NA.csv", header=TRUE)
dat2 <- read.csv("http://mgimond.github.io/ES218/Data/Income_education.csv", header=TRUE)Dataset dat1
dat1 consists of grain yields by north american countries and by year. The dataset was downloaded from http://faostat3.fao.org/ in June of 2014.
A subset of dat1 will be used in later tutorials in both a wide form and a long form. The wide form will be called dat1w and will be a table of year vs. crop yields.
library(dplyr)
library(tidyr)
dat1w <- dat1 %>%
filter(Information == "Yield (Hg/Ha)",
Country =="United States of America",
Crop %in% c("Oats", "Maize", "Barley", "Buckwheat","Rye")) %>%
select(Year, Crop, Value) %>%
pivot_wider(names_from = Crop, values_from="Value")
head(dat1w)# A tibble: 6 x 6
Year Barley Buckwheat Maize Oats Rye
<int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2012 36533. 10446. 77442. 21975. 17576.
2 2011 37432. 10299. 92366. 20492. 16409.
3 2010 39345. 10555. 95923. 23057. 17602.
4 2009 39287. 10931. 103376. 24210. 17418.
5 2008 34195. 10000 96596. 22836. 18618.
6 2007 32278. 10000 94584. 21565. 15719.The long form version of the subset will be called dat1l and will be a long form representation of dat1w (yield by crop and year).
dat1l <- pivot_longer(dat1w, names_to = "Crop", values_to = "Yield", cols=2:6)
head(dat1l, 10)# A tibble: 10 x 3
Year Crop Yield
<int> <chr> <dbl>
1 2012 Barley 36533.
2 2012 Buckwheat 10446.
3 2012 Maize 77442.
4 2012 Oats 21975.
5 2012 Rye 17576.
6 2011 Barley 37432.
7 2011 Buckwheat 10299.
8 2011 Maize 92366.
9 2011 Oats 20492.
10 2011 Rye 16409.Another subset will be used in subsequent exercises and will consist of total yields for each year by crop and country.
dat1l2 <- dat1 %>%
filter(Information == "Yield (Hg/Ha)",
Crop %in% c("Oats", "Maize", "Barley", "Buckwheat","Rye")) %>%
select( Year, Crop, Country, Yield = Value) # Note that we are renaming the Value field
head(dat1l2,15) Year Crop Country Yield
1 2012 Barley Canada 38894.66
2 2012 Maize Canada 83611.49
3 2012 Oats Canada 24954.79
4 2012 Rye Canada 38056.86
5 2012 Barley United States of America 36533.24
6 2012 Buckwheat United States of America 10445.86
7 2012 Maize United States of America 77441.67
8 2012 Oats United States of America 21974.70
9 2012 Rye United States of America 17575.73
10 2011 Barley Canada 32796.43
11 2011 Maize Canada 88946.49
12 2011 Oats Canada 29109.36
13 2011 Rye Canada 24676.81
14 2011 Barley United States of America 37431.96
15 2011 Buckwheat United States of America 10299.05Dataset dat2
A tidy table: dat2b
dat2 consists of county income and educational attainment for both the male and female population. A codebook available here provides descriptions for the different codes. We will remove the cases (rows) from dat2 for which values are missing (i.e. cases having a NA designation) since these rows will serve no purpose (such cases may be associated with counties having no year-round residents or a resident population too small for data dissemination).
dat2 <- na.omit(dat2)As with dat1, we will create a tidy version of dat2 for use with packages such as ggplot2.
The dat2 dataset has income data broken down by educational attainment and gender aggregated at the county level. It would therefore be convenient for plot operations if two variables, Gender and (educational) Level, were added to the long table version of dat2.
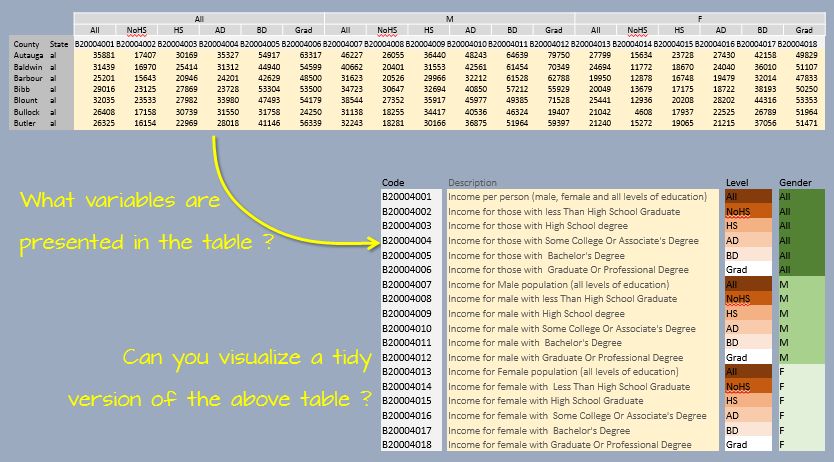
We will first generate a lookup table, Edu.Gend, of variable elements that will match each census category (e.g. B20004001, B20004002, …) to its matching pair of Level and Gender types.
We will also create a State/Region lookup table, st.reg, that will store two variables: the two letter state abbreviation variable State and its matching region variable Region. R has a built-in vector called state.region that assigns a region to each state. However, you’ll note that this vector only has region names but makes no reference to states. It’s intended to be used with another built-in data vector called state.abb or state.name. We will combine state.abb with state.region to create st.reg. We will also need to convert the uppercase state abbreviations to lower case using tolower so that they match the dat2’s lowercase state abbreviations. Note that D.C. is not included in the built-in states dataset, so we will add this record the st.reg table and assign D.C. to the South region.
Finally, the two tables, Edu.gend and st.reg, will be joined to the long version of dat2 such that each observation will be assigned a Level, Gender and Region.
library(stringr)
# Create a variable/Level/Gender join table
Edu.Gend <- data.frame(
variable = paste("B200040", str_pad(1:18, width=2 , pad="0"),sep="" ),
Level = rep(c("All", "NoHS","HS","AD","BD","Grad"), times=3),
Gender = rep(c("All", "M","F"), each=6) )
# Create a region/state join table
st.reg <- data.frame(State = tolower(state.abb), Region = state.region)
st.reg <- rbind(st.reg , data.frame(State="dc", Region="South") )
# Start the piping operations
dat2b <- dat2 %>%
pivot_longer(names_to = "variable", values_to = "value", cols=-1:-2) %>%
left_join(Edu.Gend, by="variable" ) %>%
select(State, County, Level, Gender, value) %>%
mutate(Level = factor(Level,
levels = c("All","NoHS","HS", "AD", "BD", "Grad"))) %>%
left_join(st.reg , by="State")
head(dat2b)# A tibble: 6 x 6
State County Level Gender value Region
<chr> <chr> <fct> <chr> <int> <fct>
1 al Autauga All All 35881 South
2 al Autauga NoHS All 17407 South
3 al Autauga HS All 30169 South
4 al Autauga AD All 35327 South
5 al Autauga BD All 54917 South
6 al Autauga Grad All 63317 South tail(dat2b)# A tibble: 6 x 6
State County Level Gender value Region
<chr> <chr> <fct> <chr> <int> <fct>
1 wy Weston All F 26530 West
2 wy Weston NoHS F 10000 West
3 wy Weston HS F 16563 West
4 wy Weston AD F 26715 West
5 wy Weston BD F 44634 West
6 wy Weston Grad F 56765 West Note that we have eliminated references to variable names such as “B20004001” from dat2b making it easier to interpret the variable names/values. Also note that we have re-leveled the educational attainment factor Level to reflect the implied order in educational attainment levels.
Spreading gender across columns: dat2c
In dat2b the gender values are lumped under the variable called Gender. In some upcoming lectures, we will want to compare male and female incomes requiring that they be assigned their own columns. We will therefore widen dat2b. We will use the pivot_wider function from the tidyr package to create a new data frame called dat2c.
dat2c <- pivot_wider(dat2b, names_from = Gender, values_from = value )
head(dat2c)# A tibble: 6 x 7
State County Level Region All M F
<chr> <chr> <fct> <fct> <int> <int> <int>
1 al Autauga All South 35881 46227 27799
2 al Autauga NoHS South 17407 26055 15634
3 al Autauga HS South 30169 36440 23728
4 al Autauga AD South 35327 48243 27430
5 al Autauga BD South 54917 64639 42158
6 al Autauga Grad South 63317 79750 49829 Manny Gimond (2021)
Manny Gimond (2021)